支持向量机
概述
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,广泛应用于分类和回归任务。SVM 的核心思想是通过寻找一个最佳的决策边界(超平面)来分隔不同类别的数据点,最大化边界距离,以提高模型的泛化能力。
支持向量机的基本概念
分离超平面:在特征空间中,SVM 试图找到一个能够最大化类别间距离的超平面。对于线性可分的数据,超平面将数据集分成两个类别。
支持向量:位于决策边界附近的样本点。支持向量是最具代表性的样本,因为它们直接影响决策边界的位置和方向。
间隔最大化:SVM 通过最大化支持向量与超平面之间的间隔来优化模型。较大的间隔通常意味着更好的泛化能力。
线性与非线性 SVM
线性 SVM:适用于线性可分的数据,即可以通过一个直线(二维)或平面(多维)进行分割。
非线性 SVM:通过引入核函数(Kernel Function),SVM 可以处理非线性可分的数据。核函数的作用是将低维数据映射到高维空间,使其在高维空间中线性可分。
- 常用的核函数包括:
- 线性核
- 多项式核
- 径向基函数(RBF)核
- Sigmoid 核
- 常用的核函数包括:
支持向量机的特点
- 高效性:在高维空间中仍然有效,尤其是当特征数大于样本数时。
- 鲁棒性:即使在特征数大于样本数的情况下,SVM 也能表现良好。
- 支持非线性分类:通过使用核技巧,SVM 能够处理非线性分布的数据。
- 数据依赖性:对于不同的数据分布和任务,SVM 的性能可能会有所差异。
应用与局限
- 应用:广泛应用于文本分类、图像识别、生物信息学等领域。
- 优点:在高维空间中表现出色,能够有效处理非线性关系。
- 缺点:对参数选取和核函数的选择敏感,训练时间可能较长,尤其在大规模数据集上。
总之,SVM 是一种强大且灵活的分类工具,尤其适合处理复杂的分类问题。其通过最大化间隔的策略,可以在许多实际应用中取得优异的性能。
实践
介绍如何使用 PyTorch 构建一个简单的 SVM 模型,以进行南瓜种子数据集的分类。此流程涵盖了数据加载、预处理、模型训练和评估等步骤。
数据集
使用 Kaggle 数据集 Pumpkin Seeds Dataset,该数据集包含不同类型南瓜种子的属性。该数据集用于多类分类问题。
导入库
导入所需的库,包括用于深度学习的 PyTorch,数据处理的 Pandas,数据可视化的 Seaborn 和 Matplotlib,以及用于数据预处理和评估的 Scikit-learn。
import torch
from torch.utils.data import DataLoader, TensorDataset
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, auc加载数据
使用 Pandas 加载数据集,并显示前五行数据:
df = pd.read_excel('../kaggle/input/Pumpkin_Seeds_Dataset.xlsx')
df.head(5)| Area | Perimeter | Major_Axis_Length | Minor_Axis_Length | Convex_Area | Equiv_Diameter | Eccentricity | Solidity | Extent | Roundness | Aspect_Ration | Compactness | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 56276 | 888.242 | 326.1485 | 220.2388 | 56831 | 267.6805 | 0.7376 | 0.9902 | 0.7453 | 0.8963 | 1.4809 | 0.8207 | Çerçevelik |
| 1 | 76631 | 1068.146 | 417.1932 | 234.2289 | 77280 | 312.3614 | 0.8275 | 0.9916 | 0.7151 | 0.8440 | 1.7811 | 0.7487 | Çerçevelik |
| 2 | 71623 | 1082.987 | 435.8328 | 211.0457 | 72663 | 301.9822 | 0.8749 | 0.9857 | 0.7400 | 0.7674 | 2.0651 | 0.6929 | Çerçevelik |
| 3 | 66458 | 992.051 | 381.5638 | 222.5322 | 67118 | 290.8899 | 0.8123 | 0.9902 | 0.7396 | 0.8486 | 1.7146 | 0.7624 | Çerçevelik |
| 4 | 66107 | 998.146 | 383.8883 | 220.4545 | 67117 | 290.1207 | 0.8187 | 0.9850 | 0.6752 | 0.8338 | 1.7413 | 0.7557 | Çerçevelik |
确保数据集的完整性:
df.info()输出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2500 entries, 0 to 2499
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 2500 non-null int64
1 Perimeter 2500 non-null float64
2 Major_Axis_Length 2500 non-null float64
3 Minor_Axis_Length 2500 non-null float64
4 Convex_Area 2500 non-null int64
5 Equiv_Diameter 2500 non-null float64
6 Eccentricity 2500 non-null float64
7 Solidity 2500 non-null float64
8 Extent 2500 non-null float64
9 Roundness 2500 non-null float64
10 Aspect_Ration 2500 non-null float64
11 Compactness 2500 non-null float64
12 Class 2500 non-null object
dtypes: float64(10), int64(2), object(1)
memory usage: 254.0+ KB查看目标变量 Class 的属性:
df.Class.unique()输出
array(['Çerçevelik', 'Ürgüp Sivrisi'], dtype=object)数据预处理
进行标签编码,并将数据集划分为训练集和测试集。然后对特征进行标准化处理。
le = LabelEncoder()
df['Class_encoded'] = le.fit_transform(df['Class'])
X = df.drop(['Class', 'Class_encoded'], axis=1)
y = df['Class_encoded']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)转换数据为 PyTorch 张量
X_train_tensor = torch.FloatTensor(X_train_scaled)
y_train_tensor = torch.FloatTensor(y_train.values).reshape(-1, 1)
X_test_tensor = torch.FloatTensor(X_test_scaled)
y_test_tensor = torch.FloatTensor(y_test.values).reshape(-1, 1)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)构建和训练模型
定义并训练 SVM 模型:
class SVM(torch.nn.Module):
def __init__(self, input_dim):
super(SVM, self).__init__()
self.linear = torch.nn.Linear(input_dim, 1)
def forward(self, x):
return self.linear(x)
model = SVM(input_dim=X_train.shape[1])
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
def hinge_loss(outputs, labels, margin=1.0):
labels = 2 * labels - 1
loss = torch.mean(torch.clamp(margin - labels * outputs, min=0))
return loss
# 训练模型
num_epochs = 500
for epoch in range(num_epochs):
for batch_X, batch_y in train_loader:
outputs = model(batch_X)
loss = hinge_loss(outputs, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')输出
Epoch [100/500], Loss: 0.6008
Epoch [200/500], Loss: 0.3839
Epoch [300/500], Loss: 0.2684
Epoch [400/500], Loss: 0.3914
Epoch [500/500], Loss: 0.4774模型评估
进行预测并使用 classification_report 输出评估指标:
model.eval()
with torch.no_grad():
y_pred = model(X_test_tensor)
y_pred_class = (y_pred >= 0).float()
y_pred_prob = torch.sigmoid(y_pred)
y_pred_np = y_pred_class.numpy().flatten()
y_test_np = y_test_tensor.numpy().flatten()
y_pred_prob_np = y_pred_prob.numpy().flatten()
print(classification_report(y_test_np, y_pred_np, digits=4))| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0.0 | 0.8229 | 0.8884 | 0.8544 | 251 |
| 1.0 | 0.8777 | 0.8072 | 0.8410 | 249 |
| Accuracy | 0.8480 | 500 | ||
| Macro Avg | 0.8503 | 0.8478 | 0.8477 | 500 |
| Weighted Avg | 0.8502 | 0.8480 | 0.8477 | 500 |
绘制混淆矩阵:
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y_test_np, y_pred_np)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Confusion Matrix')
plt.show()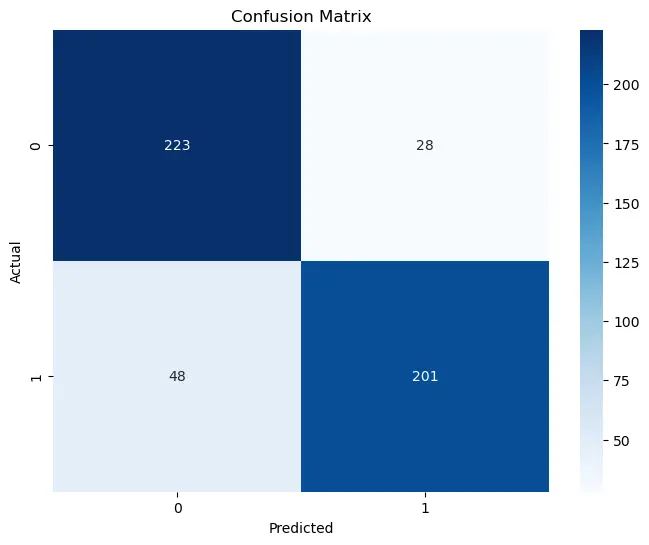
计算并绘制 ROC 曲线和 AUC 值:
fpr, tpr, _ = roc_curve(y_test_np, y_pred_prob_np)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.4f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()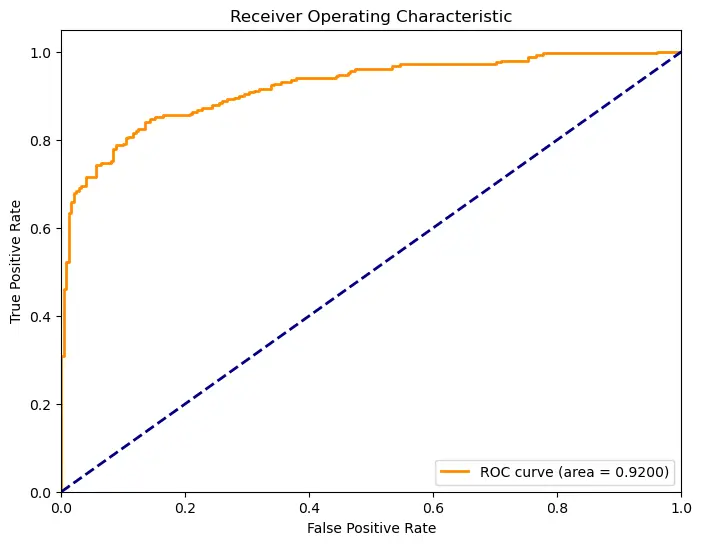
以上是对使用 PyTorch 进行 SVM 模型训练的完整步骤,包括数据预处理、模型构建和评估。
